comparing means

“Are these two things the same?”
Often, we want to know if our study subjects contain different amounts of certain analytes. For example, “Does this lake over here contain more potassium than that lake over there?” For this, we need statistical tests. Here, we will have a look at comparing mean values for analyte abundance in situations with two samples and in situations with more than two samples.
I find many of the concepts discussed in this chapter easier to think about with an example in mind. For that, suppose that you are an analytical chemist on Hawaii that is studying the chemistry of the island’s aquifers. you have the data set hawaii_aquifers. You can see in the output below the structure of the data set - we have 990 measurements of a 9 different analytes in multiple wells that draw on a set of 10 aquifers.
hawaii_aquifers
## # A tibble: 954 × 6
## aquifer_code well_name longitude latitude analyte
## <chr> <chr> <dbl> <dbl> <chr>
## 1 aquifer_1 Alewa_Heights_Sp… NA NA SiO2
## 2 aquifer_1 Alewa_Heights_Sp… NA NA Cl
## 3 aquifer_1 Alewa_Heights_Sp… NA NA Mg
## 4 aquifer_1 Alewa_Heights_Sp… NA NA Na
## 5 aquifer_1 Alewa_Heights_Sp… NA NA K
## 6 aquifer_1 Alewa_Heights_Sp… NA NA SO4
## 7 aquifer_1 Alewa_Heights_Sp… NA NA HCO3
## 8 aquifer_1 Alewa_Heights_Sp… NA NA dissol…
## 9 aquifer_1 Alewa_Heights_Sp… NA NA Ca
## 10 aquifer_1 Beretania_High_S… NA NA SiO2
## # ℹ 944 more rows
## # ℹ 1 more variable: abundance <dbl>
unique(hawaii_aquifers$aquifer_code)
## [1] "aquifer_1" "aquifer_2" "aquifer_3" "aquifer_4"
## [5] "aquifer_5" "aquifer_6" "aquifer_7" "aquifer_8"
## [9] "aquifer_9" "aquifer_10"Importantly, there are many wells that draw on each aquifer, as shown in the graph below.
hawaii_aquifers %>%
select(aquifer_code, well_name) %>%
group_by(aquifer_code) %>%
summarize(n_wells = length(unique(well_name))) -> aquifers_summarized
aquifers_summarized
## # A tibble: 10 × 2
## aquifer_code n_wells
## <chr> <int>
## 1 aquifer_1 12
## 2 aquifer_10 7
## 3 aquifer_2 5
## 4 aquifer_3 3
## 5 aquifer_4 16
## 6 aquifer_5 4
## 7 aquifer_6 12
## 8 aquifer_7 9
## 9 aquifer_8 3
## 10 aquifer_9 30
ggplot(aquifers_summarized) + geom_col(aes(x = n_wells, y = aquifer_code))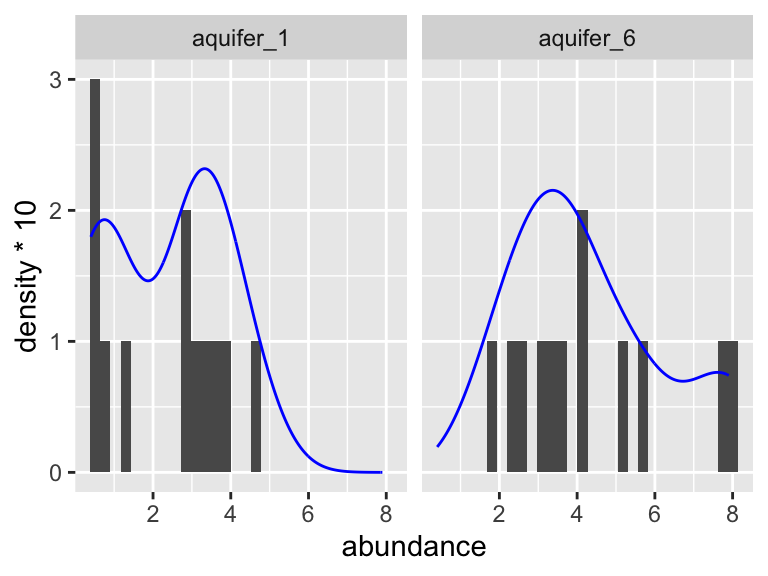
definitions
populations and independent measurements: When we are comparing means, we are comparing two sets of values. It is important to consider where these values came from in the first place. In particular, it is usually useful to think of these values as representatives of larger populations. In the example of our aquifer data set, we can think of the measurements from different wells drawing on the same aquifer as independent measurements of the “population” (i.e. the aquifer).
the null hypothesis: When we conduct a statistical test, we are testing the null hypothesis. The null (think “default”) hypothesis is that there is no difference bewteen the means (hence the name “null”). In the example of our aquifers, let’s say that we’re interested in whether two aquifers have different abundances of potassium - in this case the null hypothesis is that they do not differ, in other words, that they have the same amount of potassium.
the p value: The p value represents the probability of getting data as extreme as our results if the null hypothesis is true. In other words - the p value is the probability that we would observe the differences we did, if in fact there were no differences in the means at all. To continue with our example: suppose we measure potassium levels in 10% of the wells that access each aquifer and find that aquifer_1 has potassium levels of 14 +/- 2 and aquifer_2 has potassium levels of 12 +/- 1. Suppose that we then conduct a statistical test and get a p value of 0.04. This means that, assuming the aquifers have the same magneisum levels (i.e. assuming the null hypothesis is true), there is a 4% chance that we would get the measured values that we did. In other words, IF the aquifers have the same potassium abundance, it is pretty unlikely that we would have obtained the measurements that we did.
Please note that the the p value is not the probability of a detected difference being a false positive. The probability of a false positive requires additional information in order to be calculated. For further discussion please see the end of this chapter.
test selection
There are many different types of statistical tests. Below is a flow chart illustrating how it is recommended that statistical tests be used in this course. You can see that there are three regimes of tests: variance and normality tests (blue), parametric tests (green), and non-parametric tests (orange):
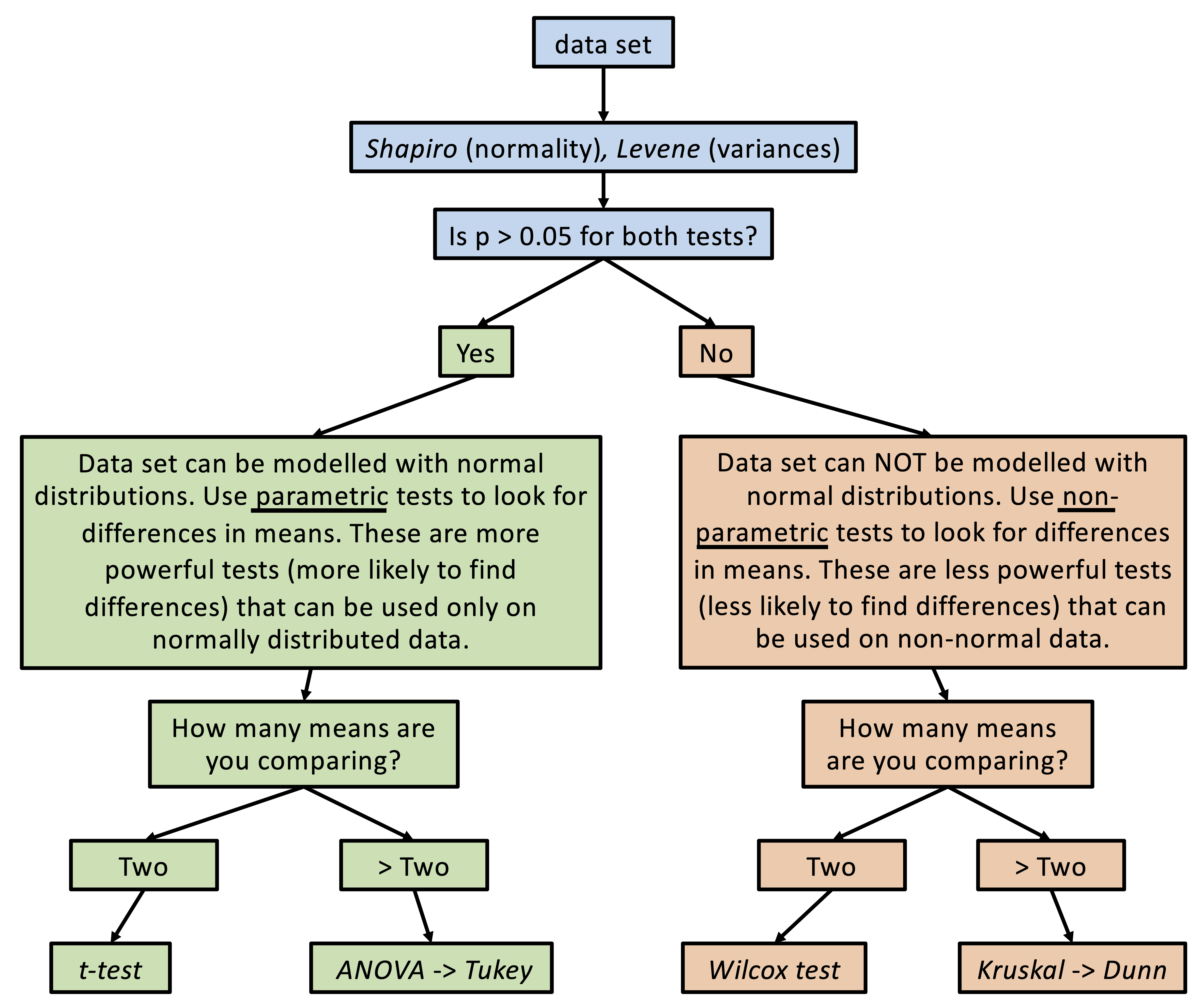
When we are comparing means, we need to first determine what kind of statistical tests we can use with our data. If (i) our data can be reasonably modelled by a normal distribution and (ii) the variances about the two means are similar, then we can use the more powerful “parametric” tests (i.e. tests that will be more likely to detect a difference in means, assuming one exists). If one of these criteria are not met, then we need to use less powerful “non-parametric” tests.
We can check our data for normality and similar variances using the Shapiro test and the Levene test. Let’s use the hawaii_aquifers data as an example, and let’s consider only the element potassium:
K_data <- hawaii_aquifers %>%
filter(analyte == "K")
K_data
## # A tibble: 106 × 6
## aquifer_code well_name longitude latitude analyte
## <chr> <chr> <dbl> <dbl> <chr>
## 1 aquifer_1 Alewa_Heights_Sp… NA NA K
## 2 aquifer_1 Beretania_High_S… NA NA K
## 3 aquifer_1 Beretania_Low_Se… NA NA K
## 4 aquifer_1 Kuliouou_Well -158. 21.3 K
## 5 aquifer_1 Manoa_Well_II -158. 21.3 K
## 6 aquifer_1 Moanalua_Wells_P… -158. 21.4 K
## 7 aquifer_1 Moanalua_Wells_P… -158. 21.4 K
## 8 aquifer_1 Moanalua_Wells_P… -158. 21.4 K
## 9 aquifer_1 Nuuanu_Aerator_W… -158. 21.4 K
## 10 aquifer_1 Palolo_Tunnel -158. 21.3 K
## # ℹ 96 more rows
## # ℹ 1 more variable: abundance <dbl>To work with two means, let’s just look at aquifers 1 and 6:
K_data_1_6 <- K_data %>%
filter(aquifer_code %in% c("aquifer_1", "aquifer_6"))
K_data_1_6
## # A tibble: 24 × 6
## aquifer_code well_name longitude latitude analyte
## <chr> <chr> <dbl> <dbl> <chr>
## 1 aquifer_1 Alewa_Heights_Sp… NA NA K
## 2 aquifer_1 Beretania_High_S… NA NA K
## 3 aquifer_1 Beretania_Low_Se… NA NA K
## 4 aquifer_1 Kuliouou_Well -158. 21.3 K
## 5 aquifer_1 Manoa_Well_II -158. 21.3 K
## 6 aquifer_1 Moanalua_Wells_P… -158. 21.4 K
## 7 aquifer_1 Moanalua_Wells_P… -158. 21.4 K
## 8 aquifer_1 Moanalua_Wells_P… -158. 21.4 K
## 9 aquifer_1 Nuuanu_Aerator_W… -158. 21.4 K
## 10 aquifer_1 Palolo_Tunnel -158. 21.3 K
## # ℹ 14 more rows
## # ℹ 1 more variable: abundance <dbl>
ggplot(K_data_1_6, aes(x = aquifer_code, y = abundance)) +
geom_boxplot() +
geom_point()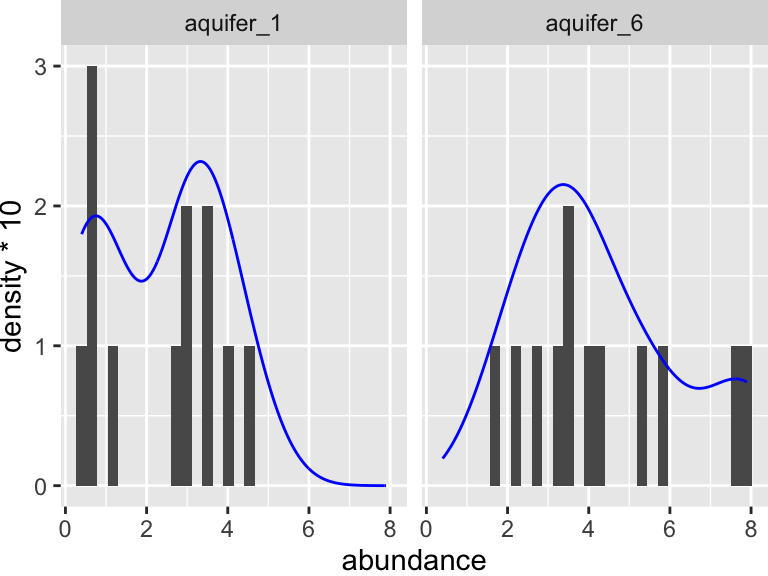
Are these data normally distributed? Do they have similar variance? Let’s get a first approximation by looking at a plot:
K_data_1_6 %>%
ggplot(aes(x = abundance)) +
geom_histogram(bins = 30) +
facet_wrap(~aquifer_code) +
geom_density(aes(y = ..density..*10), color = "blue")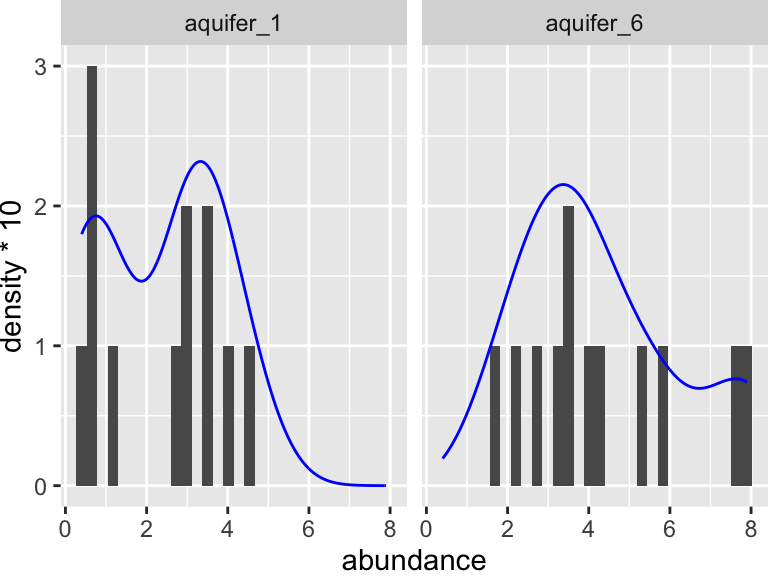
Based on this graphic, it’s hard to say! Let’s use a statistical test to help. When we want to run the Shaprio test, we are looking to see if each group has normally distributed here (here group is “aquifer_code”, i.e. aquifer_1 and aquifer_6). This means we need to group_by(aquifer_code) before we run the test:
K_data_1_6 %>%
group_by(aquifer_code) %>%
shapiroTest(abundance)
## # A tibble: 2 × 4
## aquifer_code variable statistic p
## <chr> <chr> <dbl> <dbl>
## 1 aquifer_1 values 0.885 0.102
## 2 aquifer_6 values 0.914 0.239Both p-values are above 0.05! This means that the distributions are not significantly different from a normal distribution. What about the variances about the two means? Are they similar? For this we need a Levene test. With that test, we are not looking within each group, but rather across groups - this means we do NOT need to group_by(aquifer_code) and should specify a y ~ x formula instead:
K_data_1_6 %>%
leveneTest(abundance ~ aquifer_code)
## # A tibble: 1 × 4
## df1 df2 statistic p
## <int> <int> <dbl> <dbl>
## 1 1 22 0.289 0.596The p-value from this test is 0.596! This means that their variances are not significantly different. If their shape is the same (normality) and their variances are the same (equal variances), then the only thing that can be different is their means. This allows us to set up our null hypothesis and calculate the probability of obtaining these different means if the two sets of observations come from an identical source.
two means
Now, since our data passed both test, this means we can use a normal t-test. A t-test is a parametric test. This means that it relies on modelling the data using a normal distribution in order to make comparisons. It is also a powerful test. This means that it is likely to detect a difference in means, assuming one is present. Let’s try it out:
K_data_1_6 %>%
tTest(abundance ~ aquifer_code)
## # A tibble: 1 × 8
## .y. group1 group2 n1 n2 statistic df p
## * <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl>
## 1 abundance aquif… aquif… 12 12 -2.75 20.5 0.0121A p-value of 0.012! This is below 0.05, meaning that if the two aquifers truly had the same mean, we would only observe a difference at least this extreme about 1.2% of the time. That gives us fairly strong evidence that the means differ. Suppose that our data had not passed the Shapiro and/or Levene tests. We would then need to use a Wilcox test. The Wilcox test is a non-parametric test, which means that it does not use a normal distribution to model the data in order to make comparisons. This means that is a less powerful test than the t-test, which means that it is less likely to detect a difference in the means, assuming there is one. For fun, let’s try that one out and compare the p-values from the two methods:
K_data_1_6 %>%
wilcoxTest(abundance ~ aquifer_code)
## # A tibble: 1 × 7
## .y. group1 group2 n1 n2 statistic p
## * <chr> <chr> <chr> <int> <int> <dbl> <dbl>
## 1 abundance aquifer_1 aquifer_6 12 12 33.5 0.0252A p-value of 0.028! This is higher than the value given by the t-test (0.012). That is because the Wilcox test is a less powerful test: it is less likely to detect differences in means, assuming they exist. Interpreting the number in the same way, if the two groups really had identical distributions, we would get results this extreme only about 2.8% of the time.
more than two means
In the previous section we compared two means. What if we want to compare means from more than two study subjects? The first step is again to determine which tests to use. Let’s consider our hawaii aquifer data again, though this time let’s use all the aquifers, not just two:
K_data <- hawaii_aquifers %>%
filter(analyte == "K")
K_data
## # A tibble: 106 × 6
## aquifer_code well_name longitude latitude analyte
## <chr> <chr> <dbl> <dbl> <chr>
## 1 aquifer_1 Alewa_Heights_Sp… NA NA K
## 2 aquifer_1 Beretania_High_S… NA NA K
## 3 aquifer_1 Beretania_Low_Se… NA NA K
## 4 aquifer_1 Kuliouou_Well -158. 21.3 K
## 5 aquifer_1 Manoa_Well_II -158. 21.3 K
## 6 aquifer_1 Moanalua_Wells_P… -158. 21.4 K
## 7 aquifer_1 Moanalua_Wells_P… -158. 21.4 K
## 8 aquifer_1 Moanalua_Wells_P… -158. 21.4 K
## 9 aquifer_1 Nuuanu_Aerator_W… -158. 21.4 K
## 10 aquifer_1 Palolo_Tunnel -158. 21.3 K
## # ℹ 96 more rows
## # ℹ 1 more variable: abundance <dbl>
ggplot(data = K_data, aes(y = aquifer_code, x = abundance)) +
geom_boxplot() +
geom_point(color = "maroon", alpha = 0.6, size = 3)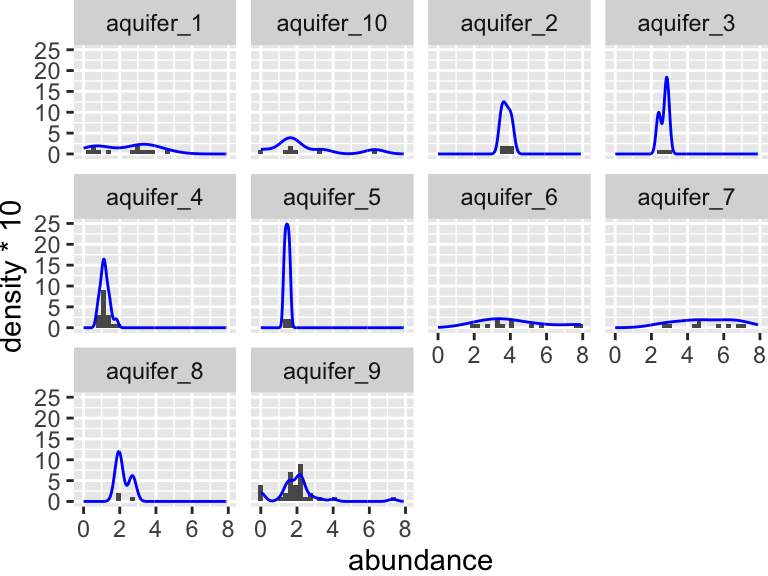
Let’s check visually to see if each group is normally distributed and to see if they have roughly equal variance:
K_data %>%
group_by(aquifer_code) %>%
ggplot(aes(x = abundance)) +
geom_histogram(bins = 30) +
facet_wrap(~aquifer_code) +
geom_density(aes(y = ..density..*10), colour = "blue")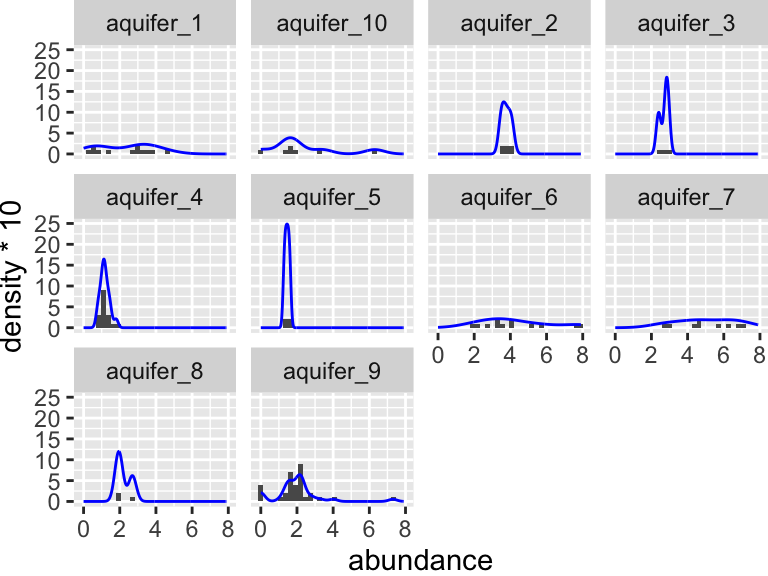
Again, it is somewhat hard to tell visually if these data are normally distributed. It seems pretty likely that they have different variances about the means, but let’s check using the Shapiro and Levene tests. Don’t forget: with the Shaprio test, we are looking within each group and so need to group_by(), with the Levene test, we are looking across groups, and so need to provide a y~x formula:
K_data %>%
group_by(aquifer_code) %>%
shapiroTest(abundance)
## # A tibble: 10 × 4
## aquifer_code variable statistic p
## <chr> <chr> <dbl> <dbl>
## 1 aquifer_1 values 0.885 0.102
## 2 aquifer_10 values 0.864 0.163
## 3 aquifer_2 values 0.913 0.459
## 4 aquifer_3 values 0.893 0.363
## 5 aquifer_4 values 0.948 0.421
## 6 aquifer_5 values 0.993 0.972
## 7 aquifer_6 values 0.914 0.239
## 8 aquifer_7 values 0.915 0.355
## 9 aquifer_8 values 0.842 0.220
## 10 aquifer_9 values 0.790 0.0000214
K_data %>%
leveneTest(abundance ~ aquifer_code)
## # A tibble: 1 × 4
## df1 df2 statistic p
## <int> <int> <dbl> <dbl>
## 1 9 96 2.95 0.00387Based on these tests, it looks like the data for aquifer 9 is significantly different from a normal distribution (Shaprio test p < 0.05), and the variances are certainly different from one another (Levene test p < 0.05).
Let’s assume for a second that our data passed these tests. This means that we could reasonably model our data with normal distributions and use a parametric test to compare means. This means that we can use an ANOVA to test for differences in means.
ANOVA, Tukey tests
We will use the anovaTest function from the package rstatix. It will tell us if any of the means in the data are statistically different from one another. However, if there are differences between the means, it will not tell us which of them are different.
K_data %>%
anovaTest(abundance ~ aquifer_code)
## ANOVA Table (type II tests)
##
## Effect DFn DFd F p p<.05 ges
## 1 aquifer_code 9 96 9.486 3.28e-10 * 0.471A pretty small p-value! Under the null hypothesis that all aquifers have the same mean, observing differences at least this extreme would be very unlikely, so we have evidence that at least one mean differs. But, WHICH are different from one another though? For this, we need to run Tukey’s Honest Significant Difference test (implemented using tukey_hsd). This will essentially run t-test on all the pairs of study subjects that we can derive from our data set (in this example, aquifer_1 vs. aquifer_2, aquifer_1 vs. aquifer_3, etc.). After that, it will correct the p-values according to the number of comparisons that it performed. This controls the rate of type I error that we can expect from the test. These corrected values are provided to us in the p.adj column.
K_data %>%
tukey_hsd(abundance ~ aquifer_code)
## # A tibble: 45 × 9
## term group1 group2 null.value estimate conf.low
## * <chr> <chr> <chr> <dbl> <dbl> <dbl>
## 1 aquifer_code aquifer… aquif… 0 0.00357 -2.04
## 2 aquifer_code aquifer… aquif… 0 1.44 -0.708
## 3 aquifer_code aquifer… aquif… 0 0.375 -2.40
## 4 aquifer_code aquifer… aquif… 0 -1.15 -2.78
## 5 aquifer_code aquifer… aquif… 0 -0.875 -3.36
## 6 aquifer_code aquifer… aquif… 0 1.98 0.228
## 7 aquifer_code aquifer… aquif… 0 2.70 0.801
## 8 aquifer_code aquifer… aquif… 0 -0.125 -2.90
## 9 aquifer_code aquifer… aquif… 0 -0.349 -1.80
## 10 aquifer_code aquifer… aquif… 0 1.44 -0.954
## # ℹ 35 more rows
## # ℹ 3 more variables: conf.high <dbl>, p.adj <dbl>,
## # p.adj.signif <chr>
# K_data %>%
# tukeyHSD(abundance ~ aquifer_code)Using the output from our tukey test, we can determine which means are similar. We can do this using the pGroups function:
groups_based_on_tukey <- K_data %>%
tukey_hsd(abundance ~ aquifer_code) %>%
pGroups()
groups_based_on_tukey
## treatment group spaced_group
## aquifer_1 aquifer_1 ab ab
## aquifer_10 aquifer_10 abc abc
## aquifer_2 aquifer_2 acd a cd
## aquifer_3 aquifer_3 abcd abcd
## aquifer_4 aquifer_4 b b
## aquifer_5 aquifer_5 ab ab
## aquifer_6 aquifer_6 cd cd
## aquifer_7 aquifer_7 d d
## aquifer_8 aquifer_8 abcd abcd
## aquifer_9 aquifer_9 ab abWe can use the output from pGroups to annotate our plot:
ggplot(data = K_data, aes(y = aquifer_code, x = abundance)) +
geom_boxplot() +
geom_point(color = "maroon", alpha = 0.6, size = 3) +
geom_text(data = groups_based_on_tukey, aes(y = treatment, x = 9, label = group))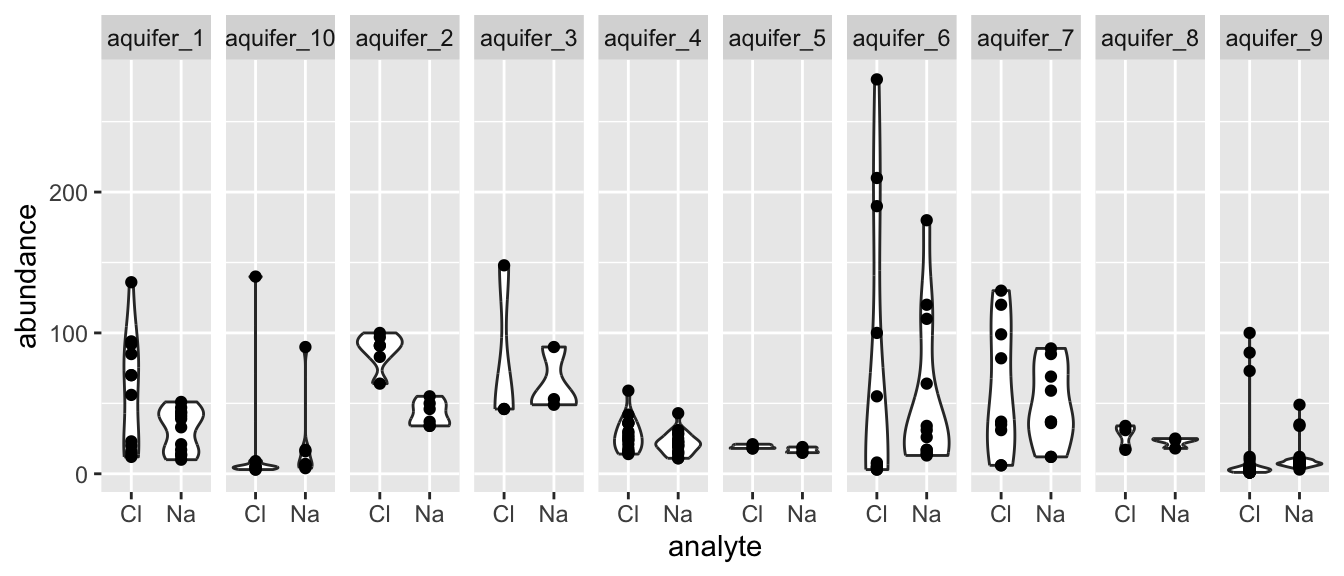
Excellent! This plot shows us, using the letters on the same line with each aquifer, which means are the same and which are different. If a letter is shared among the labels in line with two aquifers, it means that their means do not differ significantly. For example, aquifer 2 and aquifer 6 both have “b” in their labels, so their means are not different - and are the same as those of aquifers 3 and 10.
Kruskal, Dunn tests
The above ANOVA example is great, but remember - our data did not pass the Shapiro or Levene tests. This means not all our data can be modelled by a normal distribution and taht we need to use a non-parametric test. The non-parametric alternative to the ANOVA is called the Kruskal test. Like the Wilcox test, it is less powerful that its parametric relative, meaning that it is less likely to detected differences, should they exist. However, since our data do not pass the Shapiro/Levene tests, we have to resort to the Kruskal test. Let’s try it out:
K_data %>%
kruskalTest(abundance ~ aquifer_code)
## # A tibble: 1 × 6
## .y. n statistic df p method
## * <chr> <int> <dbl> <int> <dbl> <chr>
## 1 abundance 106 55.9 9 0.00000000807 Kruskal-Wal…A pretty small p-value! This is higher than the p-value from running ANOVA on the same data (remember, the Kruskal test is less powerful). Never the less, the value is still well below 0.05, meaning that data this extreme would be rare if all group medians were identical. So, how do we determine WHICH are different from one another? When we ran ANOVA the follow-up test (the post hoc test) was Tukey’s HSD. After the Kruskal test, the post hoc test we use is the Dunn test. Let’s try:
K_data %>%
dunnTest(abundance ~ aquifer_code)
## # A tibble: 45 × 9
## .y. group1 group2 n1 n2 statistic p p.adj
## * <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl>
## 1 abunda… aquif… aquif… 12 7 -0.194 0.846 1
## 2 abunda… aquif… aquif… 12 6 2.24 0.0254 0.736
## 3 abunda… aquif… aquif… 12 3 0.866 0.387 1
## 4 abunda… aquif… aquif… 12 17 -2.65 0.00806 0.266
## 5 abunda… aquif… aquif… 12 4 -1.12 0.263 1
## 6 abunda… aquif… aquif… 12 12 2.51 0.0121 0.388
## 7 abunda… aquif… aquif… 12 9 3.01 0.00257 0.100
## 8 abunda… aquif… aquif… 12 3 0.143 0.886 1
## 9 abunda… aquif… aquif… 12 33 -0.470 0.639 1
## 10 abunda… aquif… aquif… 7 6 2.17 0.0296 0.830
## # ℹ 35 more rows
## # ℹ 1 more variable: p.adj.signif <chr>This gives us adjusted p-values for all pairwise comparisons. Once again, we can use pGroups() to give us a compact letter display for each group, which can then be used to annotate the plot:
groups_based_on_dunn <- K_data %>%
dunnTest(abundance ~ aquifer_code) %>%
pGroups()
groups_based_on_dunn
## treatment group spaced_group
## aquifer_1 aquifer_1 abcd abcd
## aquifer_10 aquifer_10 abcd abcd
## aquifer_2 aquifer_2 abc abc
## aquifer_3 aquifer_3 abcd abcd
## aquifer_4 aquifer_4 d d
## aquifer_5 aquifer_5 acd a cd
## aquifer_6 aquifer_6 ab ab
## aquifer_7 aquifer_7 b b
## aquifer_8 aquifer_8 abcd abcd
## aquifer_9 aquifer_9 cd cd
ggplot(data = K_data, aes(y = aquifer_code, x = abundance)) +
geom_boxplot() +
geom_point(color = "black", alpha = 0.4, size = 2) +
scale_x_continuous(name = "Potassium abundance", breaks = seq(0,10,1)) +
scale_y_discrete(name = "Aquifer code") +
geom_text(data = groups_based_on_dunn, aes(y = treatment, x = 9, label = group)) +
theme_bw()
Note that these groupings are different from those generated by ANOVA/Tukey.
pairs of means
Oftentimes we have more than two means to compare, but rather than wanting to compare all means at once, we want to compare them in a pairwise fashion. For example, suppose we want to know if any of the aquifers contain different amounts of Na and Cl. We are not interested in testing for differences among all values of Na and Cl, rather, we want to test all pairs of Na and Cl values arising from each aquifer. That is to say, we want to compare the means in each facet of the plot below:
hawaii_aquifers %>%
filter(analyte %in% c("Na", "Cl")) %>%
ggplot(aes(x = analyte, y = abundance)) + geom_violin() + geom_point() + facet_grid(.~aquifer_code)
Fortunately, we can use an approach that is very similar to the what we’ve learned in the earlier portions of this chapter, just with minor modifications. Let’s have a look! We start with the Shapiro and Levene tests, as usual (note that we group using two variables when using the Shapiro test so that each analyte within each aquifer is considered as an individual distribution):
hawaii_aquifers %>%
filter(analyte %in% c("Na", "Cl")) %>%
group_by(analyte, aquifer_code) %>%
shapiroTest(abundance)
## Note: Found a group with exactly 3 data points where at least two were identical.
## A tiny bit of noise was added to these data points, because the Shapiro–Wilk test
## p-value can be artificially low in such edge cases due to test mechanics.
## Consider carefully whether you want to interpret the results of the test, even with noise added.
## # A tibble: 20 × 5
## analyte aquifer_code variable statistic p
## <chr> <chr> <chr> <dbl> <dbl>
## 1 Cl aquifer_1 values 0.900 1.59e- 1
## 2 Cl aquifer_10 values 0.486 1.09e- 5
## 3 Cl aquifer_2 values 0.869 2.24e- 1
## 4 Cl aquifer_3 values 0.750 1.98e- 6
## 5 Cl aquifer_4 values 0.903 7.49e- 2
## 6 Cl aquifer_5 values 0.849 2.24e- 1
## 7 Cl aquifer_6 values 0.741 2.15e- 3
## 8 Cl aquifer_7 values 0.893 2.12e- 1
## 9 Cl aquifer_8 values 0.878 3.17e- 1
## 10 Cl aquifer_9 values 0.420 2.68e-10
## 11 Na aquifer_1 values 0.886 1.06e- 1
## 12 Na aquifer_10 values 0.593 2.26e- 4
## 13 Na aquifer_2 values 0.884 2.88e- 1
## 14 Na aquifer_3 values 0.822 1.69e- 1
## 15 Na aquifer_4 values 0.933 2.41e- 1
## 16 Na aquifer_5 values 0.827 1.61e- 1
## 17 Na aquifer_6 values 0.764 3.80e- 3
## 18 Na aquifer_7 values 0.915 3.51e- 1
## 19 Na aquifer_8 values 0.855 2.53e- 1
## 20 Na aquifer_9 values 0.531 3.97e- 9Looks like some of those distributions are significantly different from normal! Let’s run the levene test anyway. Note that for this particular case of the Levene test, we are interested in testing whether each pair of distributions has similar variances. For that we need to feed the Levene test data that is grouped by aquifer_code (so that it tests each pair as a group), then we need to specify the y ~ x formula (which in this case is abundance ~ analyte):
hawaii_aquifers %>%
filter(analyte %in% c("Na", "Cl")) %>%
group_by(aquifer_code) %>%
leveneTest(abundance ~ analyte)
## # A tibble: 10 × 5
## aquifer_code df1 df2 statistic p
## <chr> <int> <int> <dbl> <dbl>
## 1 aquifer_1 1 22 10.5 0.00375
## 2 aquifer_10 1 12 0.0535 0.821
## 3 aquifer_2 1 10 0.0243 0.879
## 4 aquifer_3 1 4 0.320 0.602
## 5 aquifer_4 1 32 1.57 0.219
## 6 aquifer_5 1 6 2 0.207
## 7 aquifer_6 1 22 1.03 0.322
## 8 aquifer_7 1 16 1.54 0.232
## 9 aquifer_8 1 4 0.515 0.512
## 10 aquifer_9 1 64 1.10 0.298It looks like the variances of the pair in aquifer 1 have significantly different variances. So - we for sure need to be using non-parametric testing. If this were a simple case of two means we would use the wilcox_test, but we have may pairs, so we will use pairwise_wilcox_test (note that with this test there are options for various styles of controlling for multiple comparisons, see: ?pairwise_wilcox_test):
hawaii_aquifers %>%
filter(analyte %in% c("Na", "Cl")) %>%
group_by(aquifer_code) %>%
pairwiseWilcoxTest(abundance~analyte)
## # A tibble: 10 × 10
## aquifer_code .y. group1 group2 n1 n2 statistic
## * <chr> <chr> <chr> <chr> <int> <int> <dbl>
## 1 aquifer_1 abundan… Cl Na 12 12 99.5
## 2 aquifer_10 abundan… Cl Na 7 7 14
## 3 aquifer_2 abundan… Cl Na 6 6 36
## 4 aquifer_3 abundan… Cl Na 3 3 3
## 5 aquifer_4 abundan… Cl Na 17 17 189
## 6 aquifer_5 abundan… Cl Na 4 4 13
## 7 aquifer_6 abundan… Cl Na 12 12 53
## 8 aquifer_7 abundan… Cl Na 9 9 42
## 9 aquifer_8 abundan… Cl Na 3 3 6
## 10 aquifer_9 abundan… Cl Na 33 33 195
## # ℹ 3 more variables: p <dbl>, p.adj <dbl>,
## # p.adj.signif <chr>Excellent! It looks like there is a statistically significant difference between the means of the abundances of Cl and Na in aquifer_2 and (surprisingly?) in aquifer_9 (perhaps due to the large number of observations?).
What would we have done if our Shaprio and Levene tests had revealed no significant differences? Well, a pairwise_TTest of course!
hawaii_aquifers %>%
filter(analyte %in% c("Na", "Cl")) %>%
group_by(aquifer_code) %>%
pairwiseTTest(abundance~analyte) -> test_output
test_output
## # A tibble: 10 × 10
## aquifer_code .y. group1 group2 n1 n2 p
## * <chr> <chr> <chr> <chr> <int> <int> <dbl>
## 1 aquifer_1 abundance Cl Na 12 12 4.69e-2
## 2 aquifer_10 abundance Cl Na 7 7 8.82e-1
## 3 aquifer_2 abundance Cl Na 6 6 3.75e-5
## 4 aquifer_3 abundance Cl Na 3 3 6.83e-1
## 5 aquifer_4 abundance Cl Na 17 17 1.03e-1
## 6 aquifer_5 abundance Cl Na 4 4 9.75e-2
## 7 aquifer_6 abundance Cl Na 12 12 5.66e-1
## 8 aquifer_7 abundance Cl Na 9 9 5.21e-1
## 9 aquifer_8 abundance Cl Na 3 3 4.28e-1
## 10 aquifer_9 abundance Cl Na 33 33 8.96e-1
## # ℹ 3 more variables: p.signif <chr>, p.adj <dbl>,
## # p.adj.signif <chr>Excellent, now we see how to run parametric and non-parametric pairwise comparisons. How do we annotate plots with the output of these tests? Here is an example:
anno <- data.frame(
xmin = test_output$group1,
xmax = test_output$group2,
y_position = c(150, 150, 150, 175, 80, 50, 300, 150, 50, 125),
text = test_output$p.signif,
text_size = 10,
text_vert_offset = 10,
text_horiz_offset = 1.5,
tip_length_xmin = 5,
tip_length_xmax = 5,
aquifer_code = test_output$aquifer_code,
hjust = 0.5,
vjust = 0.5
)
hawaii_aquifers %>%
filter(analyte %in% c("Na", "Cl")) %>%
ggplot(aes(x = analyte, y = abundance)) +
geom_violin(fill = "gold", color = "black") +
geom_point(shape = 21, fill = "maroon", color = "black") +
facet_grid(.~aquifer_code) +
geomSignif(data = anno, orientation = "horizontal") +
scale_x_discrete(name = "Analyte") +
scale_y_continuous(name = "Abundance") +
theme_bw() +
theme(
text = element_text(size = 16)
)
further reading
Comparing Multiple Means in R. Datanovia’s step-by-step tutorial shows how to run one-way and repeated-measures ANOVA in R, diagnose assumptions, and follow up with Tukey or pairwise comparisons using tidyverse-friendly code.
Parametric vs. Nonparametric Tests. Jim Frost breaks down when parametric tests are appropriate, the trade-offs of switching to rank-based alternatives, and how violation of assumptions affects power and interpretation.
The p value wars. A short commentary by Ulrich Dirnagl capturing the ongoing debates about redefining statistical significance, the historical context of p < 0.05, and the risks of rigid thresholds versus broader inferential thinking.
Common statistical mistakes in biomedical research. The authors catalog frequent errors such as double dipping, underpowered designs, and misreported effect sizes, pairing each with pragmatic fixes for both authors and reviewers.
Wolfgang Huber on tiny p-values. Huber explains why extremely small p-values emerge in high-throughput experiments, how to think about multiplicity and effect sizes, and what to report alongside adjusted significance.